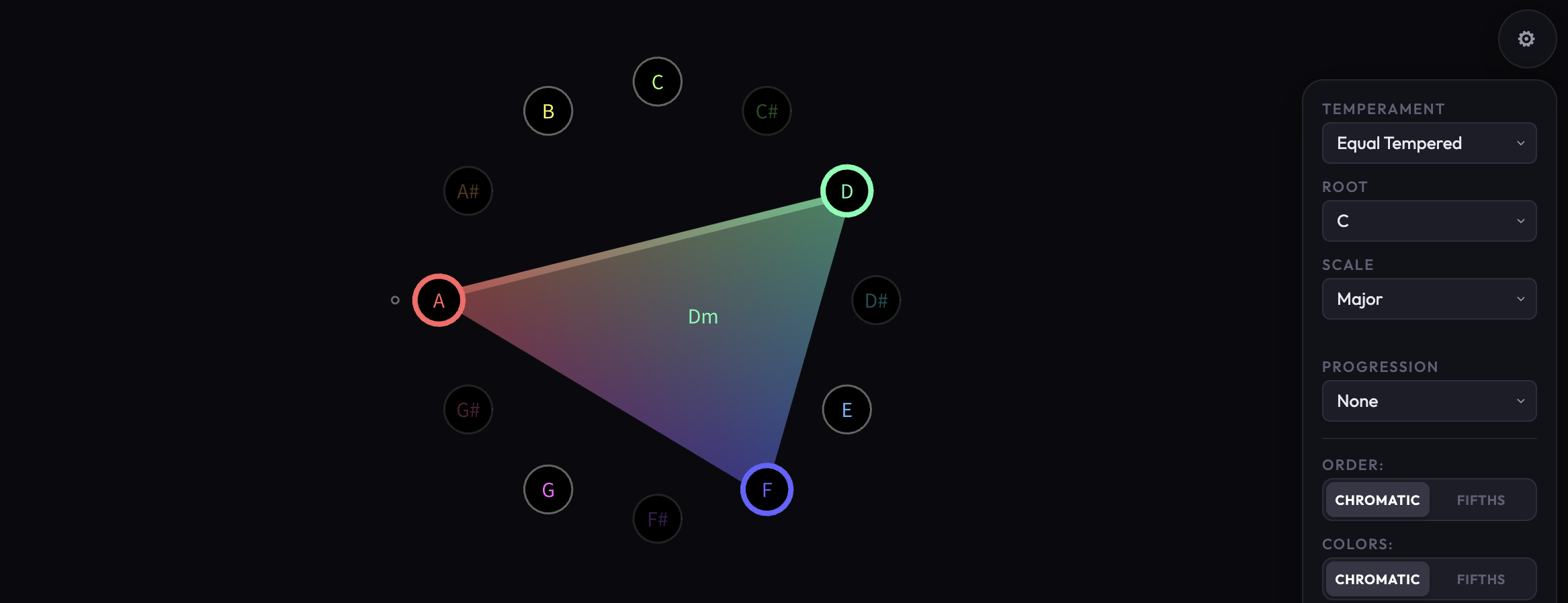
Way back in 2013, I wrote a music theory explorer using the Java-based processing.org framework. I’ve always wanted to port it to the wonderful web-native p5.js, but couldn’t find the time to complete it. With a little LLM help I was able to do so in a couple of hours and even add a few features; check it out at https://oneilsh.github.io/Interval/.
The monarchr package makes it easy to work with Knowledge Graph (KG) data in R. Designed with
the Monarch Initiative in mind, the package supports any KG
in the standard KGX format, including those at https://kghub.org/, via either files for Neo4j-hosted graph databases. With
monarchr I wanted to design a tidy-inspired API around pipes, allowing users to query nodes and flexibly expand those nodes to fetch their surrounding neighborhood accorind to specific criteria. Backed by the amazing tidygraph and igraph packages (and a lot of help from neo2r), graphs may be filtered, joined, transitively aggregated, and analyzed.
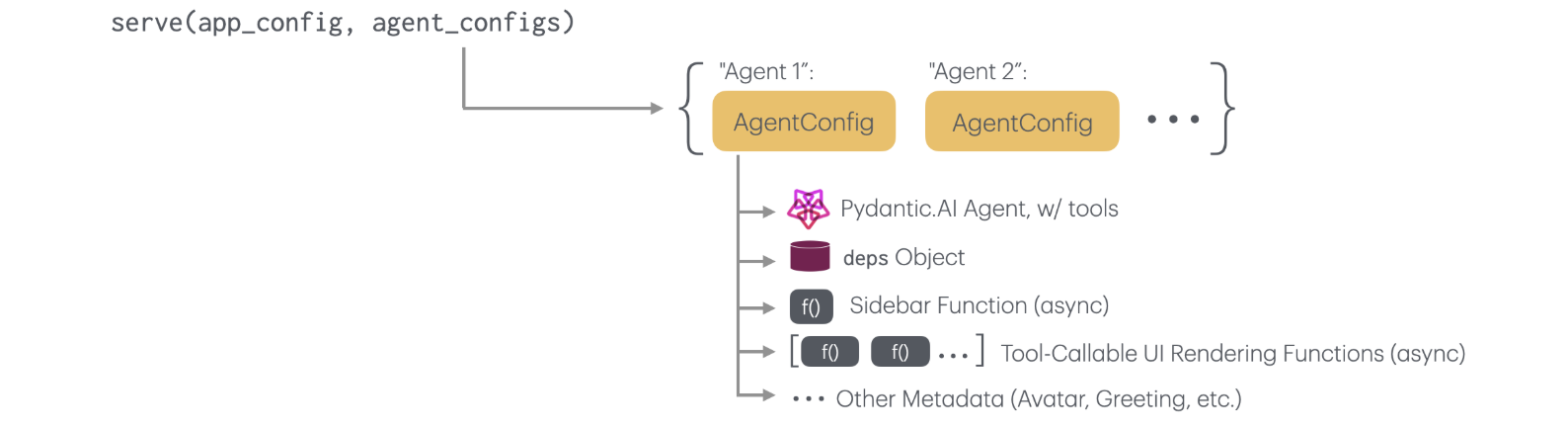
Opaiui (oh-pie-you-eye) provides a rapid prototyping framework for LLM-backed chat applications based on Pydantic.AI and Streamlit.
While Streamlit provides relatively high-level components for chat input/output and display, wiring up a framework like Pydantic.AI is still a fair amount of work, particularly if one wants to support streaming responses and tool-calling provenance, or other features. Opaiui provides high-level integration points between Pydantic.AI agents, and a number of features for AI-mediated UI elements:
In this study, published in npj Digital Medicine, I apply an unsupervised learning technique known as Latent Dirichlet Allocation (LDA) to identify condition clusters across millions of patients in the N3C database. Such clusters are not guaranteed to be related to COVID-19, however. To identify those that are, we look at how patients are assigned to clusters before and after COVID-19 infection, integrating the probabilistic nature of LDA and supervised models (repeated-measures logistic regression) to predict how patients will migrate toward or away from a cluster post-infection, moderated by demographic factors such as age, sex, and wave of infection.
What if an AI could perform a literature review for you? Here I illustrate using Large Language Models (LLMs) and related technologies for
search and summarization. We use OpenAI's gpt-3.5-turbo (ChatGPT) and gpt-4 models, SentenceTransformers sentence embeddings, and the PubMed API to
build a first-pass literature summarizer, that 1) designs an effective search query given a user question, 2) retrieves and indexes pubmed abstracts with embeddings, 3) selects the top-matching abstracts for individual summarization in light of the original question, and 4) summarizes the summaries including references.
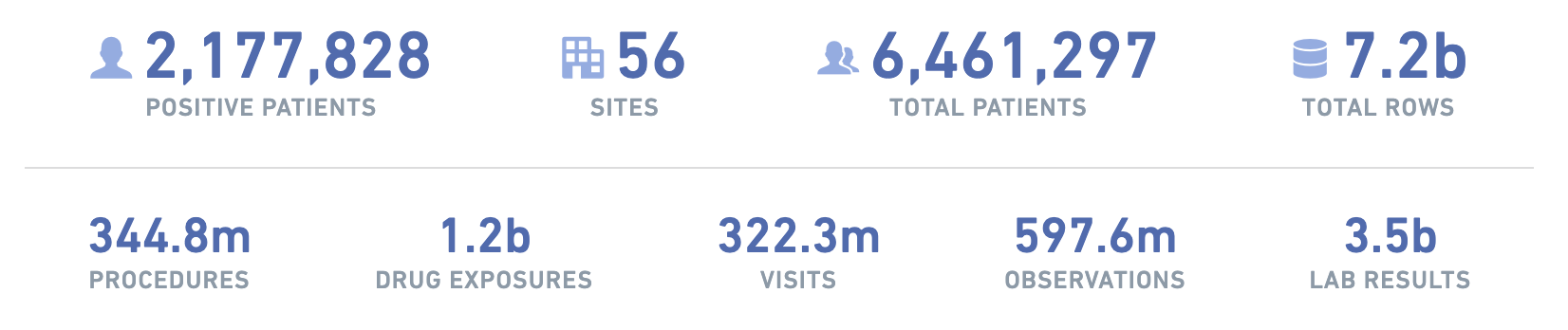
Since starting a new position with the TISLab in early 2020, my primary effort has been as Training Coordinator with the National COVID Cohort Collaborative, or N3C. This truly amazing group of scientists, clinicians, and engineers has accomplished something unique in US healthcare history: sourcing electronic health records from hospital systems and medical centers nationwide (56 and counting) into a single unified database of clinical records related to the COVID-19 pandemic.
These 7 billion rows of data representing 6.5 million people (1/3 COVID-positive, 2/3 COVID-negative) are accessible only via a FedRAMP-certified analysis ’enclave’ with rigorous application critia. As of this writing 219 research institutions have signed data use agreements for all their employees and students, over 1,500 researchers from around the US and beyond are collaborating on over 200 research projects, and the publications committee is now tracking multiple N3C-supported journal submissions per week.
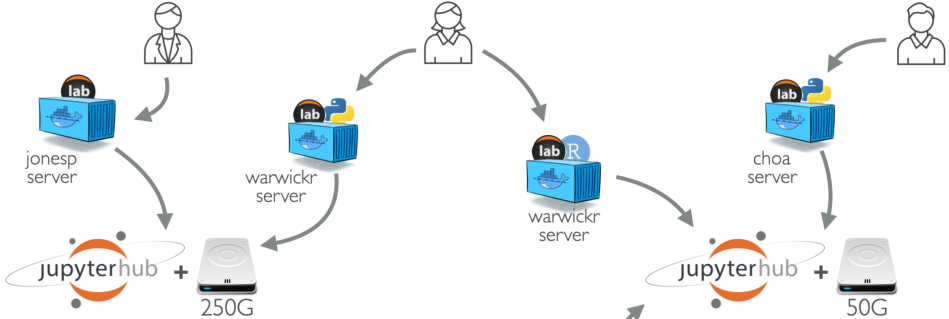
DS@OSU was a project I had the priveledge of co-leading (along with Dr. Robin Pappas) in collaboration with Oregon State UIT. Driven by a broadly recognized need to enable accessible and scalable infrastructure for data science (and related) instruction, we embarked on campus-wide needs assessments, a steering committee, technical and faculty advisory committees, fact-finding sessions with peer institutions, and eventually platform implemention.
Based on the Zero to JupyterHub kubernetes-based deployment pattern, DS@OSU provides a number of additional custom features:
TidyTensor is an R package for inspecting and manipulating tensors (multidimensional arrays). i
It provides an improved print() function for summarizing structure, named tensors,
conversion to data frames, and high-level manipulation functions. Designed to complement the
excellent keras package, functionality is layered on top of base R types.
TidyTensor was inspired by a workshop I taught in deep learning with R, and a desire to
explain and explore tensors in a more intuitive way.